Articles
Sequa Context Engine Benchmark
March 4, 2026

AI agents are great at getting the first 80% right. They write code that compiles, maybe even passes tests. But they create new utility functions instead of using the ones your team built six months ago. They pick the wrong abstraction. They ignore conventions that exist for good reasons but were never written down. The agent is not stupid. It is missing context.
The Problem Is Information, Not Intelligence
Every AI coding session starts from zero. The agent sees the files in your repository and nothing else. It does not know your team moved from REST to GraphQL for new endpoints. It does not know why the authentication middleware is structured the way it is. It always behaves like a day one employee.
The instinct is to wait for the next model release. But a model that is 10x better at reasoning still cannot reason about conventions it has never seen. It cannot reuse a utility function it does not know exists. The ceiling for AI agent quality is not model capability. It is the context those models operate on.
Context Engineering Should Not Be One Engineer's Side Quest
Right now, context engineering is an individual responsibility. Each developer crafts their own prompts, occasionally modifies the CLAUDE.md file, builds their own mental model of what the agent needs to know. There is no shared process, no collaboration, no single source of truth that the whole team contributes to and every agent session benefits from.
This does not scale. When one engineer discovers that the agent needs to know about your event bus conventions, that knowledge lives in their prompt file and nowhere else. The rest of the team hits the same wall independently. Context becomes fragmented, duplicated, and stale.
Context engineering needs to be a team practice, not a solo effort. The same way teams collaborate on code through pull requests, they need a shared space to collaborate on the context their AI agents operate on.
Measuring the Impact of Shared Context
We built Sequa to make this possible. Sequa is a context layer for AI coding agents that automatically builds and maintains a structured understanding of your product: architecture, conventions, design decisions, domain model, and the reasoning behind how things were built. It gives teams a shared place to curate and refine that context together, and it stays current automatically as the codebase evolves. Agents access it through MCP, so every Claude Code or Cursor session works from the same understanding.
To measure the impact, we designed a benchmark grounded in real-world engineering work rather than synthetic tasks.
Benchmark Methodology
We selected 104 real GitHub issues from four mature, actively maintained open-source repositories: n8n, Ghostfolio, Cal.com, and Twenty. These codebases were chosen for their architectural complexity, active development communities, and well-documented contribution histories.
Each issue was paired with its actual merged pull request as the ground truth reference solution. We filtered the dataset to complex, non-refactoring tasks. Issues that require changes across multiple files and demand genuine understanding of the codebase to solve well. Simple single-file changes, documentation updates, and pure refactoring work were excluded.
Every task was executed twice by Claude Code (Sonnet 4), under identical default configurations. The only difference between runs was the presence of the Sequa MCP connection in the second run. No additional prompting, tool configuration, or manual intervention was applied in either case.
An independent LLM judge (Gemini 3) then evaluated both solutions against the real merged PR, scoring each on five quality dimensions on a 0.0–1.0 scale.
Results
We filtered the scored results to tasks where at least one solution demonstrated meaningful correctness. Across these tasks, using only Sequa's automatically generated base context with zero manual customization:
In two thirds of tasks, Claude Code with Sequa MCP produced measurably better solutions. In the remaining third, there was no improvement over default Claude Code.
Here is what the judge measured and what improved:
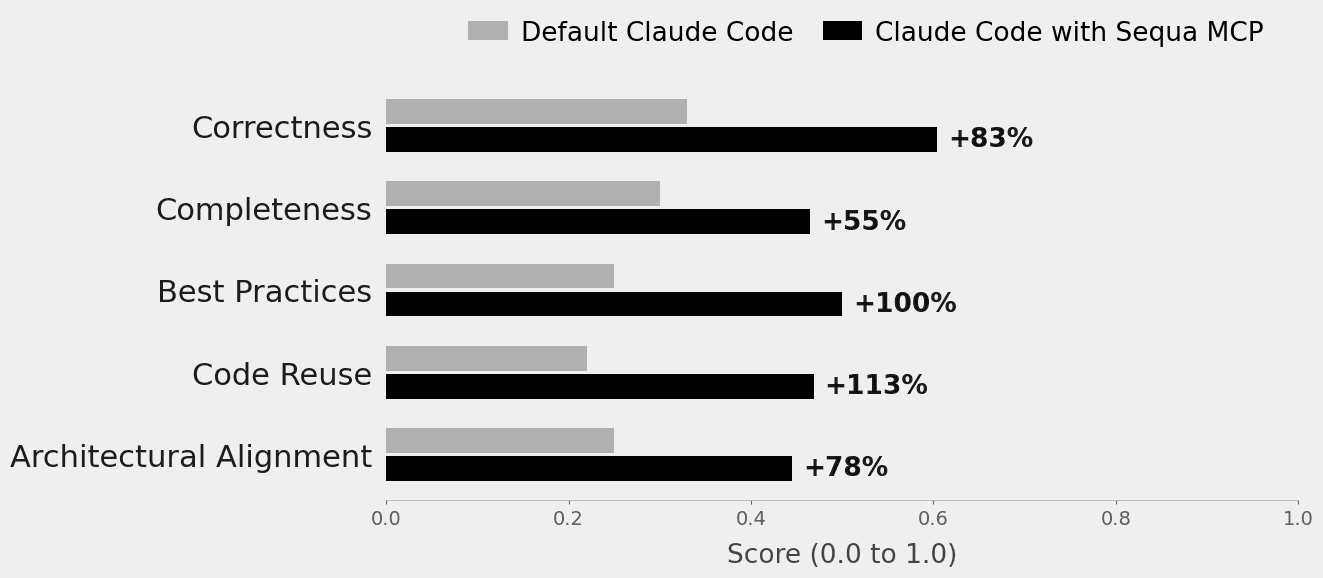
Correctness (+83%) scores whether the solution actually fixes the issue. From no meaningful changes at 0.0, through partial fixes, to fully resolved at 1.0. The most fundamental question: does it work?
Completeness (+55%) measures whether the solution covers all aspects of the issue. Default Claude Code tends to fix the core problem but miss edge cases, related updates, or necessary adjustments elsewhere in the codebase.
Best Practices (+100%) evaluates whether the code follows established quality patterns: proper error handling, clean architecture, appropriate abstractions. With context, the agent knows what "good" looks like in your specific codebase, not just in general.
Code Reuse (+113%) is where context shines the most. This scores whether the agent leverages existing utilities, helpers, and patterns instead of reinventing them. Default Claude Code has no way to discover a utility function three directories away. With Sequa, it knows what already exists.
Architectural Alignment (+78%) captures the big picture: does the solution demonstrate understanding of the project's architecture, domain model, and cross-cutting concerns? A low score means the agent treated the task generically. A high score means it understood how the change fits into the broader system. This is the difference between code that technically works and code that belongs in your product.
Benchmark Limitations
This benchmark was designed to isolate the effect of automatically generated context under controlled conditions. Several constraints define the scope of these results.
First, the context layer used in this benchmark was generated entirely from static code analysis. No external knowledge sources were connected, no Slack history, no issue trackers, no wikis, no design documents, no RFCs. The context engine had access to code and nothing else. We are conducting ongoing research into the impact of supplementary context sources on solution quality, and internal testings show that each additional source meaningfully increases context coverage, particularly for conventions and architectural decisions that are discussed but never formalized in code.
Second, no human on the team reviewed or refined the generated context for this benchmark. Sequa's context layer is designed as a collaborative artifact. Teams can correct inaccuracies, add domain knowledge, flag conventions, and encode decisions that only humans carry. Every refinement propagates to all future agent sessions across the entire team.
The results presented here represent what a fully automated, code-only, zero-curation context engine achieves on day one. With connected knowledge sources and active team curation, these numbers improve substantially.
Why This Matters Now
The question is not whether AI agents will write more of your code. They already are. The question is whether they will write code that fits your product or code that technically works but creates maintenance debt.
The benchmark data is clear: context is the lever. Not better models, not better prompts from individual engineers, but structured, maintained, team-curated context that gives agents the same understanding your best engineers have. The teams that make context engineering a shared practice will ship faster. The rest will keep fixing the same AI-generated code over and over.